Big Data has been around for a long time and the tools to handle it but amongst other things they were very expensive. A big driver of companies now starting to utilise their big data is a number of open source software projects if you read about big data these names will definitely come up with many being Apache projects.
Hadoop integration was added way back in version 0.6 of Cassandra. It began with MapReduce support. Since then the support has matured significantly and now includes native support for Apache Pig and Apache Hive. Cassandra's Hadoop support implements the same interface as HDFS to achieve input data locality.
DataStax, a company that creates products around Cassandra, has created a simplified way to use Hadoop with Cassandra and built it into its DataStax Enterprise product. For details on DSE, see
A brief example of a company moving over to Cassandra and Hadoop with some reasons why they did:
The first place we started was by thinking about our data, now that we were moving out of the “validation” and into the “scaling” phase of our business.
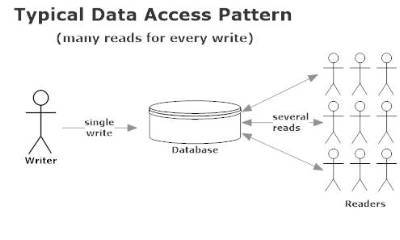
Analytics is a weird business when it comes to read / write characteristics and data access patterns. In most CRUD applications, mobile apps, and e-commerce software you tend to see read / write characteristics like this:
This isn’t a controversial opinion – it’s just a fact of how most networked applications work. Data is read far more often than it’s written.
That’s why all relational databases and most document databases are optimized to cache frequently read items into memory – because that’s how the data is used in the vast majority of use cases.
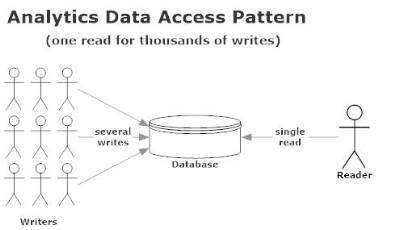
In analytics though, the relationship is inverted:
By the time a MarkedUp customer views a report on our dashboard, that data has been written to anywhere from 1,000 to 10,000,000 times since they viewed their report last. In analytics, data is written multiple orders of magnitude more frequently than it’s read. This has implications on Database choice.
Based on all of the above criteria, we narrowed down the field of contenders to the following:
The last major piece of our stack is our map/reduce engine, which is powered by Hive and Hadoop.
Hadoop is notoriously slow, but that’s ok. We don’t serve live queries with it – we batch data periodically and use Hive to re-insert it back into Cassandra.
Hive is our tool of choice for most queries, because it’s an abstraction that feels intuitive to our entire team (lots of SQL experience) and is easy to extend and test on the fly. We’ve found it easy to tune and it integrates well with the rest of DataStax Enterprise Edition.
It’s important to think carefully about your data and your technology choices, and sometimes it can be difficult to do that in a data vacuum. Cassandra, Hive, and Hadoop ended up being the right tools for us at this stage, but we only arrived at that conclusion after actually doing live acceptance tests and performance tests.